
|

|
Synergistic Software Customization:
Framework, Algorithms, and Tools
|
Objective
Object-oriented languages such as C++, C#, and Java have brought us software libraries that are large, well tested, and easy to re-use. However, we have reached a point where many applications are dwarfed by the libraries they import. As programmers continue to develop layers of useful libraries, programmers can work at higher and higher levels of abstraction. The trade-off for a programmer is straightforward: if 10 lines of code that rely on massive, well-tested libraries can do the same as 100 lines of code, most programmers will write the 10 lines of code. As the size and power of libraries increase, the security and efficiency of application software decrease. The problem is that the massive libraries usually add complexity and bloat to even simple tasks. Thus, we pay for the high programmer productivity with software that has a large attack surface and inefficient execution. The overarching goal of the proposed project is to exploit synergy of static and dynamic program analysis techniques to tackle the security and inefficiency problems in modern software systems.
Approach
The following figure shows the scope of our proposed work. Our tools enter the picture after software is installed and after the user uses the application. Specifically, the people who are responsible for deployment can use our tools to customize and optimize the software. Our tools will remove little used functionality, decrease run-time bloat, and specialize libraries to what is actually used. A unique strength of our project is that our three research thrusts have synergy. The synergy makes our thrusts feed on each other and make them stronger together. Our project focuses on Java at a late stage so we assume that no Java source code is available; our tools work solely on binary Java bytecode.
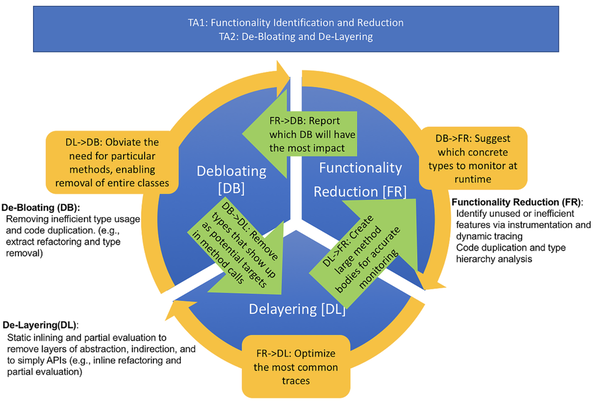
On functionality reduction (FR), our goal is to select features and code regions to be removed from applications and underlying libraries. In order not to require any kinds of human effort in tagging features or functionality, we envision a completely automated approach: (1) unused functionality by finding never-invoked APIs or finding de-facto use of the interfaces, with many default constants or configuration options, much smaller than what is afforded by the original APIs, (2) inefficient objects where a faster-performing type may be used to replace a slower-performing type, and (3) redundant program logic evidenced by code duplication in binaries and/or an over-blown class hierarchy with many sibling or sub-classes.
On de-bloating (DB), our goal is to permanently, statically remove the unnecessary features and code regions. (1) We will design a set of static techniques that merge functionalities of related types with the goal of removing types that are not strictly necessary. (2) We will design an automated clone removal technique that factorizes redundant code in binaries. On de-layering (DL), our goal is to reduce indirections and layers of abstractions through static inlining and partial evaluation. Our specialization technique will remove redundant features, partially evaluate generic code, and change allocation site to use the fastest-performing type. |